
Nota editorial (2025): publicado originalmente en 2020. Se añadió una versión estructurada con fines enciclopédicos. El texto original se conserva íntegro como parte del archivo histórico.
«`html
Artículo sobre la pandemia de COVID-19 y el impacto del sesgo en los índices de mortalidad
Este artículo analiza las diferencias regionales en los índices de mortalidad por COVID-19, destacando la influencia del sesgo de muestreo y el papel potencial que podrían desempeñar pruebas aleatorias para obtener una visión más precisa. Se discute la importancia del análisis causal dentro del marco estadístico para comprender mejor estas variaciones.
- Prueba Aleatoria: Un método ideal que permite evitar sesgos de selección y reducir distorsiones en las estadísticas, aunque su implementación plena requiere consideraciones prácticas y psicológicas. La obtención de muestras aleatorias presenta desafíos como el autoseleccionismo.
- Sesgo: Los índices presentados por los datos pueden ser sesgados debido a que se obtienen principalmente de individuos en hospitales o quienes han padecido síntomas graves, ignorando aquellos sanos y no hospitalizados.
- Análisis Causal: Los modelos causales son esenciales para comprender los procesos subyacentes que generan la información disponible. Esto ayuda a explicar diferencias entre países sin atribuirlas únicamente a una mejor o peor gestión del virus.
- Modelos Bayesian: El uso de un enfoque bayesiano para actualizar las probabilidades variables desconocidas es fundamental dentro del modelo causal propuesto, lo que permite comprender con mayor exactitud la situación real.
- Implicaciones Legales y Psicológicas: Se considera urgente el establecimiento de protocolos nacionales para pruebas aleatorias. Los desafíos prácticos incluyen logística, voluntariado legalizado, psicología social respecto a la ansiedad generalizada por enfermedad.
- Ejemplos Internacionales: Corea del Sur ha propuesto y ejecutado con éxito pruebas aleatorias. España intentó este enfoque pero encontró dificultades debido a la falta de fiabilidad inicial de los kits para COVID-19.
- Diferencias Regionales: El artículo destaca que, aunque se pueden hacer comparaciones entre países utilizando datos del mismo período, estos no siempre reflejan diferencias en la gestión o prevalencia de COVID-19 debido a variaciones demográficas y métodos informativos.
«La necesidad urgente es el establecimiento de protocolos nacionales para pruebas aleatorias.» – Expertise from author’s work.
«`
Preguntas frecuentes
«`html
Frequently Asked Questions (FAQs) About the Impact of Bias in Mortality Indices and Random Testing during COVID-19 Pandemic
What is a random test, and why are they considered ideal for reducing bias?
A random test ensures that no selection or biases influence the sample collection. However, implementing them fully requires practical considerations like autoselectionism.
How does sampling bias affect mortality indices during a pandemic such as COVID-19?
Sampling bias can skew mortality data since it often includes individuals from hospitals or those with severe symptoms, overlooking the broader population.
Why is causal analysis important in understanding regional differences during a pandemic like COVID-19?
Causal analysis helps to uncover underlying reasons for data variations between countries and does not solely attribute them to management effectiveness or lack thereof.
What role do Bayesian models play in understanding the real situation during a pandemic like COVID-19?
Bayesian models are vital for updating unknown probability variables, leading to more accurate reflections of reality within causal analysis frameworks.
Why is establishing national protocols for random testing considered urgent during a pandemic such as COVID-19?
Establishing these protocols is essential due to the practical and psychological challenges, including logistics, legal voluntary participation, and general anxiety regarding illness.
What are some international examples of testing strategies during COVID-19?
Corea del Sur successfully implemented random tests. Spain faced issues due to unreliable initial test kits but has since improved the reliability for future use.
How can regional differences impact comparisons of mortality indices during a pandemic like COVID-19?
Regional variances, including demographic and methodological discrepancies between countries, may distort the actual comparison despite having data from the same time period.
«The urgent need is to establish national protocols for random testing.» – Expertise from author’s work.
05 FAQs Based on COVID-19 Article: Impact of Bias and Random Testing Strategies, Including International Comparisons
Texto original (2020)
Este artículo analiza las diferencias en los índices de mortalidad por COVID-19 entre varios países y la influencia del sesgo de muestreo. Examina también el papel potencial que podrían desempeñar pruebas aleatorias para obtener una visión más precisa, discutiendo las ventajas e inconvenientes respectivos a este método en un contexto pandemico y destacando los desafíos prácticos de su implementación. El autor destaca la importancia del análisis causal dentro del marco estadístico para comprender mejor estas variaciones regionales, además menciona que se está trabajando en modelos basados en este tipo de inferencias y consideran expandirlos a factores sociodemográficos. El artículo culmina señalando la necesidad urgente del establecimiento de protocolos nacionales para el desarrollo de pruebas aleatorias, citando ejemplos internacionales como Corea del Sur que han propuesto y ejecutado con éxito tales estrategias; mientras destaca las dificultades prácticas en países como España. Se enfatiza la importancia de un protocolo legalizado para el voluntariado a pruebas aleatorias, junto al análisis cuidadoso del impacto psicológico que puede derivar una pandemia sobre los individuos y su influencia en los resultados estadísticos.
Supongamos que pretendemos hacer una estimación sobre cuántos propietarios de vehículos hay en Reino Unido y, de ellos, cuántos tienen un Ford Fiesta, pero solo disponemos de datos acerca de cuántas personas han visitado exposiciones de novedades de Ford en el último año. Si tenemos en cuenta el sesgo de la muestra, en el caso de que el 10 % de los visitantes de exposiciones fueran propietarios de un Fiesta, se produciría una sobreestimación de la proporción de propietarios de Ford Fiesta en todo el país.
La misma línea siguen las estimaciones de los índices de mortalidad de personas con COVID-19. En Reino Unido, sin ir más lejos, casi todas las pruebas se realizan con personas ya hospitalizadas que presentan síntomas de la enfermedad. En el momento en el que se redacta este artículo, hay 29 474 casos confirmados de COVID-19 en Reino Unido (análogos a los propietarios de coches que visitan una exposición), de los cuales han fallecido 2 352 (propietarios de Ford Fiesta que visitaron una exposición). Sin embargo, esta estimación no tiene en cuenta a todas aquellas personas que presentan síntomas leves o, directamente, no los presentan.
Al inferir que el índice de mortalidad de la COVID-19 se sitúa en un 8 % (2 352 de 29 474), se está ignorando a una gran cantidad de personas que, a pesar de sufrir la enfermedad, no son hospitalizadas ni han fallecido (análogas a los propietarios de vehículos que no visitaron una exposición ni tienen un Ford Fiesta). Es, por lo tanto, un error equivalente al de concluir que el 10 % de todos los propietarios de coches en Reino Unido tienen un Fiesta.
Podemos encontrar ejemplos llamativos de conclusiones de este tipo. El Servicio de Pruebas de la COVID-19 de la Universidad de Oxford está trabajando en un exhaustivo análisis estadístico que reconoce sesgos de selección potenciales y añade intervalos de confianza que demuestran la magnitud que podría adquirir el error en la (potencialmente engañosa) proporción de muertes de pacientes positivos en COVID-19.
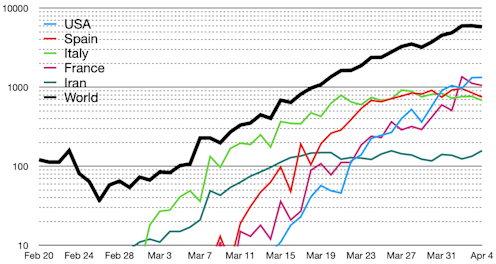
El grupo de trabajo destaca varios factores que pueden suponer amplias diferencias entre países. Por ejemplo, el promedio del 8 % del “índice de mortalidad” de Reino Unido es una cifra escandalosamente alta comparada con el 0,74 % de Alemania. Estos factores incluyen distintas variables demográficas, como el porcentaje de personas de la tercera edad dentro de la población, así como la manera de informar sobre las causas de los fallecimientos. Por ejemplo, en algunos países todas las personas que mueren tras haber sido diagnosticadas COVID-19 son registradas como decesos por dicha enfermedad, aunque no fuera la causa principal, mientras que otras personas pueden morir por el virus que la provoca sin haber recibido un diagnóstico relacionado.
Sin embargo, los modelos estadísticos no incorporan explicaciones causales explícitas que podrían permitir desarrollar inferencias significativas a partir de los datos disponibles, incluyendo la información extraída de los test del virus.

Author provided
Hemos elaborado un prototipo inicial de un modelo causal cuya estructura se puede apreciar en la imagen de arriba. Las flechas que unen las diferentes variables muestran su interdependencia en un modelo como este.
Estas relaciones, junto con otras variables desconocidas, son consideradas probabilidades. Al introducir la información en forma de variables conocidas y específicas, las probabilidades variables desconocidas son actualizadas empleando un método llamado inferencia bayesiana. El modelo expone el índice de mortalidad de la COVID-19 como una función de los métodos de muestreo, análisis e informe, ya que es determinado por el índice de infecciones del grupo de población más vulnerable.
Por lo tanto, resulta sencillo observar diferencias entre los índices de mortalidad de varios países. Esto se debe a que han aplicado políticas de muestreo e información distintas; no necesariamente tiene que obedecer a una mejor o peor gestión del virus o a que este haya infectado a un mayor o menor número de personas.
Con un modelo causal que explique los procesos mediante los cuales se genera la información, podemos comprender con mayor exactitud las diferencias entre países, así como averiguar de forma más precisa el índice real de población infectada y los índices de mortalidad extraídos de los datos de los que disponemos. Este modelo podría ampliarse para incluir factores demográficos, así como la distancia social y otros métodos de prevención. Hemos desarrollado modelos enfocados al tratamiento de problemas similares que, actualmente, se encuentran recabando información con el fin de completar el tipo de modelo (aún en ciernes) que presentamos en la imagen anterior.
Pruebas aleatorias
Al carecer de un sistema de pruebas que abarque toda la comunidad, la alternativa para acercarnos a las cifras de personas con COVID-19 que son asintomáticas o se han recuperado reside en los análisis aleatorios a la población. Para conocer los índices reales de infección y mortalidad necesitamos saber cuántas personas son asintomáticas. Además, las pruebas aleatorias permitirían averiguar cuál es la eficacia de los test (índices de falsos positivos y falsos negativos).
Así, las pruebas aleatorias se erigen en el método más eficaz para evitar los sesgos de selección y reducir las distorsiones que se aprecian en las estadísticas. Lo ideal, a su vez, sería que las pruebas fueran combinadas con modelos causales.

SamaraHeisz5/Shutterstock
Actualmente, no parece figurar entre los planes de ningún país el establecimiento de un protocolo estatal para el desarrollo de pruebas aleatorias a la comunidad. España lo intentó, pero se precisaban volúmenes considerables de test rápidos para detectar la COVID-19 y el Gobierno descubrió que algunos de los test llegados de China mostraban una fiabilidad y precisión muy bajas (un 30 %), lo que se traducía en abultadas cifras de falsos positivos.
Países como Noruega han propuesto la implantación de las pruebas aleatorias, pero aún existe cierta incertidumbre en torno a cómo instar legislativamente a los ciudadanos a someterse a las pruebas y de qué manera se podría constituir un protocolo de aleatoriedad apropiado. En Islandia se están llevando a cabo muestreos voluntarios que han cubierto ya al 3 % de la población, pero no son aleatorios. Algunos países que gozan de sistemas de pruebas a gran escala se podrían acercar a la aleatoriedad deseada, como es el caso de Corea del Sur.
La razón por la cual resulta tan complicado el desarrollo de pruebas aleatorias se debe a que es necesario tener en cuenta varios factores prácticos y psicológicos. ¿Cómo obtener muestras aleatorias? La colección de muestras procedentes de voluntarios podría no ser suficiente, ya que no evita el sesgo de autoselección.
Durante la pandemia de gripe A de 2009-2010, producida por el virus H1N1, la ansiedad generalizada dio lugar a una enfermedad psicogénica de masas. Este fenómeno se produce cuando la hipersensibilidad a síntomas particulares lleva a que personas sanas se autodiagnostiquen el virus, lo cual significa que mostrarían una especial predisposición a hacerse las pruebas. Esta situación podría, en parte, contribuir a la inflación de los índices de falsos positivos si la sensibilidad y especificidad de los test no se comprende en su totalidad.
Si bien el sesgo de autoselección no puede ser eliminado, podría verse reducido por un trabajo de campo. Esto exigiría la petición de muestras voluntarias a la población de lugares en los que, incluso en cuarentena, se mostrarían dispuestos a someterse a las pruebas. Además, habrían de recogerse también muestras de aquellos individuos que se han recluido en sus casas por voluntad propia.
En cualquier caso, se deberían explicar las limitaciones de las estadísticas al ser expuestas en las comparecencias ante los medios. Y cualquier dato relevante para la población y los individuos que la componen debería ser descrito con precisión. A este respecto, entendemos que se están cometiendo fallos considerables de comunicación en medio de la crisis actual.
![]()
![]()
Norman Fenton es director de Agena Ltd, una empresa especializada en la gestión de riesgos para sistemas críticos que utilizan redes bayesianas. También recibe actualmente financiación de la EPSRC en el marco del proyecto EP/P009964/1: PAMBAYESIAN: Patient Managed decision-support using Bayes Networks
Magda Osman recibe fondos de ESRC, NIHR, EPSRC, MRC, ACE, DSTL and MoJ.
Martin Neil es director de Agena Ltd, una empresa especializada en la gestión de riesgos para sistemas críticos que utilizan redes bayesianas.
Scott McLachlan no recibe salario, ni ejerce labores de consultoría, ni posee acciones, ni recibe financiación de ninguna compañía u organización que pueda obtener beneficio de este artículo, y ha declarado carecer de vínculos relevantes más allá del cargo académico citado.
Fuente: The Conversation (Creative Commons)
Author: Norman Fenton, Professor of Risk and Information Management, Queen Mary University of London